Day 0 Pitfalls: Where Plans Collide with Reality
Preparation defines outcomes. However, most Day 0 efforts assume OSV functions like VMware, designed more to be flexible and GUI-driven. This assumption can lead to quick failures. There are enough operational differences that it can stall or halt the VMware to OpenShift Virtualization migration.
The transition to OSV from VMware presents a steep learning curve, which can challenge infrastructure teams. New operational processes (e.g driver updates and network isolation) may feel overwhelming, and existing automation tools could struggle during this change.
Hardware, Storage, and Networking Complexity
Provisioning layers like Ironic and Metal3 demand flat networks and ISO-driven workflows. Enterprise networks, full of VLANs and segmented zones, do not fit cleanly. Small misalignments in topology ripple into large-scale failures.
The pre-requisites for installation require collaboration with your server, storage, network, and security teams. These early design decisions will impact both the deployment and continuous operations. OSV installers depend on the right storage classes (RWX-capable), SR-IOV networking, and CPU virtualization flags (VT-x/AMD-V) enabled in BIOS.
Building infrastructure that is designed to automate the deployment of workloads needs to be treated with the same goal; we need to automate the infrastructure operations to reduce the toil and effort.
Install Fragility
OpenShift’s installer was built for developers. It expects ideal conditions, not legacy infrastructure. Minor changes, such as firmware mismatches, BIOS differences, or storage configuration variations, can halt progress. VMware admins, used to simpler installs, are not as comfortable in OpenShift and OSV.
If the cluster install has drift, misaligned versions, or partially failed operators, OSV will fail silently or get blocked during install. Even a simple CRD mismatch can halt a deployment and require manual intervention. These problems are amplified at scale.
Lifecycle management in OSV is fundamentally different from how VMware operates. Making more repeatable, automated processes is a must-have to be able to deploy and operate OpenShift for any team at any scale.
Process Mismatch
VMware operations run on predictable GUIs and structured workflows. OpenShift Virtualization replaces those with YAML files, CLI tools, and automation pipelines that expose every dependency. What used to take a few clicks (e.g. adding hosts, cloning VMs, or attaching storage) now requires authoring manifests, managing operator versions, and validating configuration across layers.
Common operational steps become friction points. Snapshots depend on the right CSI drivers. Network isolation shifts from GUI settings to CNI definitions. Even patching or scaling workloads requires GitOps or Ansible pipelines instead of vCenter tasks. For VMware admins, this feels like trading certainty for syntax.
You’re facing both a tooling gap and a process shift. VMware’s “don’t break it” culture rewards control and careful upgrades. OSV expects the opposite: workloads are meant to be torn down and rebuilt, not repaired. The habits that once created stability now increase the risk on Day 1.
RackN bridges this mismatch by standardizing how infrastructure is prepared, validated, and automated before OSV deployment. Ops teams gain a predictable, versioned process that aligns VMware-style operational discipline with Kubernetes-style automation.
Day 1 Realities: When Execution Meets Resistance
If Day 0 reveals issues, Day 1 amplifies them. Deployment and migration put theory into action, requiring teams to address conflicting expectations. This situation can lead to increased:
- Toil and Manual Waste – Failed resets consume hours of effort. Debugging YAML and rerunning pods become routine, leaving VMware admins frustrated and burned out.
- Conversion Resistance – Years of investment in custom scripts and processes turn into sunk costs. Teams hesitate to abandon proven workflows for untested ones.
- Lab vs. Production Trap – Pilots often succeed in controlled labs, but production introduces compliance scans, authentication layers, and scale challenges. What works in testing often fails in real-world environments.
Day 1 teaches that technology alone isn’t the issue. The problem is operational readiness. Without it, the transition becomes a cycle of failure and resistance.
RackN, with Digital Rebar, smooths this transition by providing predictable, versioned automation across both VMware and Kubernetes environments. Your teams get a familiar, reliable way to provision infrastructure and deploy VMs so they can focus on adapting to the new operating model without fighting Day 0/Day 1 failures.
The Economic Costs: When OpenShift Deployment Delays Stack Up
Executives are often pitched OSV pilots under the assumption of quick payback. Day 0 and Day 1 delays erode that confidence. What appears to be a quick VMware exit turns out to be an expensive detour. What’s worse is that this is often a board-level initiative to migrate virtualization operations to a future-ready platform. Delays turn into double-licensing and disjointed operations processes.
Hidden Costs Surface Quickly
- License Burden – Red Hat Advanced Cluster Management (ACM) is often sold as a mandatory component. Yet it doesn’t fix the Day 0/Day 1 problems for OSV and OpenShift deployment, and adds to your license costs.
- Consulting and Bespoke Scripting – Repeated failures often prompt enterprises to seek outside consultants and develop ad hoc scripts. Each fix adds expense, risk, and process rigidity but not maturity.
- Slow Time-to-Value – Leaders expecting measurable VMware replacement progress are facing stalled POCs and timelines slipping. Trust erodes, and budget confidence fades.
All of these challenges result in both direct and indirect costs. The table below maps the most common hurdles to their hidden financial and operational impacts.
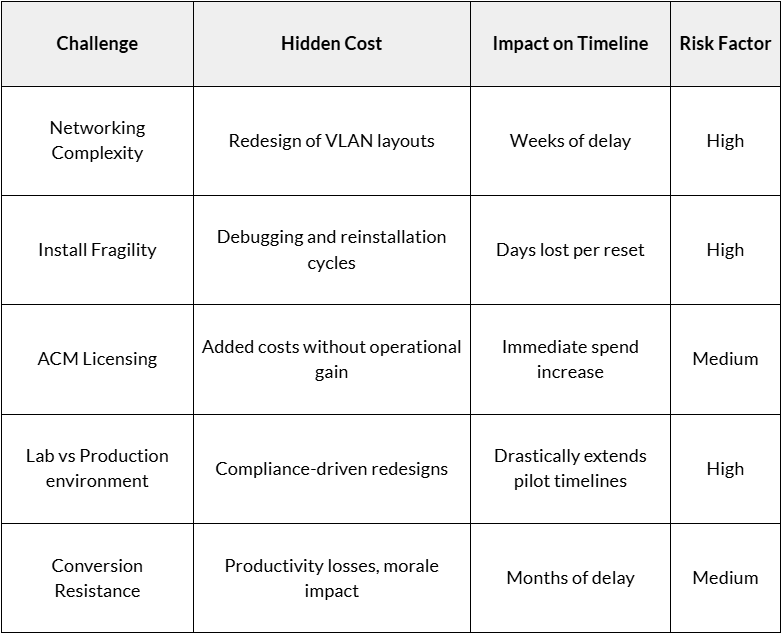
Costs are not just financial. They also show up in wasted time, team confidence, and stalled migrations that eat up valuable cycles for infrastructure and operations teams.
The Human Factor: Bridging VMware and Kubernetes Cultures
Behind the technical and economic hurdles lies the human one. Day 0 and Day 1 bring together two groups with different priorities.
- VMware professionals value stability, predictability, and return on existing investments. They tend to think from the infrastructure up.
- Kubernetes operators embrace flexibility, iteration, and automation. Kubernetes and OpenShift operators often think from the application down instead of infrastructure up
It’s not a matter of right or wrong. Both mindsets bring strengths. But without translation, OSV adoption becomes a cultural standoff.
Translation, Not Conflict
OSV doesn’t have to be a conflict zone. It can be a translation zone. VMware admins shouldn’t be forced to instantly learn YAML or adopt a developer-first mindset, just as Kubernetes operators and SREs shouldn’t have to slow down their automation practices to accommodate legacy workflows. Both bring valuable strengths; VMware teams with their precision and control, Kubernetes teams with their speed and adaptability.
Where these groups clash isn’t in skill but in rhythm. VMware admins think in terms of stability, snapshots, and maintenance windows. Kubernetes operators think in pipelines, rollouts, and automation loops. One team prefers stability; the other prefers automation-centricity and immutability. Without a translation layer, those differences create operational drag instead of progress.
RackN provides that translation. By integrating OSV installs with existing enterprise processes, RackN gives VMware admins a path into automation without losing their structure, and gives Kubernetes and SRE teams consistent, versioned workflows that don’t depend on fragile handoffs. It’s a shared operational language that allows both groups to move faster together.
Migrating from VMware to OSV shouldn’t feel like a rebrand. The transition should feel like growth in operational maturity. And while licensing pressures have pushed many teams to consider OpenShift, the real savings come from reduced friction, fewer failed pilots, and faster time-to-value.
The Way Forward: Building Operational Maturity from Day 0
RackN helps leaders align technical adoption with strategic priorities. The hurdles that appear on Day 0 and Day 1 are not fixed barriers. They reflect gaps in preparation rather than impossibility. Enterprises that approach these stages as production-critical discover that many of the issues, like fragile installs, compliance surprises, and cultural resistance, can be avoided with the right foundation.
Building the right foundation requires discipline. Treat your early pilots with the same rigor as production deployments. Networks must be designed to reflect real-world production conditions, rather than relying on simplified lab shortcuts. Compliance checks need to be integrated from the very first installation attempts, so failures surface early. Just as important, VMware’s proven stability practices should be mapped into Kubernetes automation.

Enterprise AI Needs a Bare Metal Pit Crew More Than a Faster GPU

OpenStack, Kubernetes, and the Hard Truth About Bare Metal

Why Do Bare Metal Servers Take a Long Time to Provision?
