Enterprise teams building AI are under constant pressure to deliver infrastructure resources faster, consistently, and securely. Business application owners and developers need GPU clusters stood up quickly for everything from real-time analytics to model training and inference. Yet the infrastructure teams responsible for making it happen (VPs of Infrastructure and VPs of Operations) keep running into the same bottleneck.
The latest hardware arrives, racks power on, and then weeks disappear while engineers chase manual BIOS settings, driver installs, network configurations, storage setup, and cluster integration across mixed fleets. The result is idle capacity, mounting costs, and frustrated stakeholders who just want their AI workloads running.
This is proven to be a lifecycle orchestration problem at the bare metal layer more than a hardware problem.
The Pit Crew Gap in AI Infrastructure
Think of a high-performance race car with a powerful engine and a skilled driver, but no pit crew. The car sits at the starting line while the race begins without it. Enterprise AI teams face the same dynamic. They invest heavily in GPUs and orchestration platforms (the car and driver), but the automation layer (the pit crew) is often overlooked or treated as an afterthought.
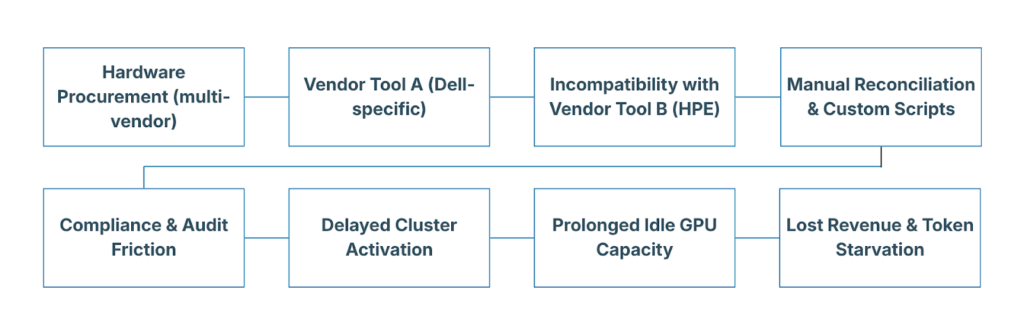
The mechanism is straightforward and repeats across every large organization. Hardware procurement lands the servers. Then the real work starts: vendor-specific tweaks, custom scripts, and integration steps that require extensive environmental, organizational, and operational knowledge.
In the lab, a single-vendor pilot might come together cleanly. In production, across multi-vendor bare metal spanning on-premises data centers and edge locations, the process stretches into four to six weeks of error-prone handoffs. The outcome is predictable: significant GPU idle time, delayed projects, and lost business value.
Let’s use a brokerage financial team as an example. They run fraud detection, risk modeling, and algorithmic trading workloads where milliseconds matter. Yet many still report around 40% idle GPU time simply because the infrastructure cannot be activated fast enough. The same pattern appears in other sectors whenever AI requirements shift quickly.
When you visualize the number of people, tools, components, and handoffs in the process, it quickly becomes painful on the eyes and on your team.

Each step involves multiple teams, handoffs, and risk of downtime or rework. The lab-to-production gap widens with every cycle.
How Vendor Lock-In Sabotages AI Deployments
Vendor-specific tools make the situation worse. Each hardware supplier (Dell, HPE, Supermicro) offers excellent management interfaces for its own ecosystem. But those tools do not speak the same language. Firmware updates, PXE booting, driver injection, and storage configuration become custom rituals that break when hardware from different suppliers is mixed. The result is configuration drift that grows harder to manage with every change.
Engineering time shifts away from supporting developers and business owners toward configuration firefighting. Multi-vendor clusters stretch from days into months. Compliance audits are painful because policies are enforced inconsistently. Every hour of idle GPU capacity is capacity that can’t deliver business outcomes.
The pattern is the same everywhere.
Proprietary dependencies do not just slow the first deployment. They make every subsequent change (new workload, firmware patch, capacity expansion) slower and riskier.
Token Anxiety and Token Starvation: The Real Cost of Idle Infrastructure
When GPU racks sit idle or take weeks to activate, the models themselves suffer. Organizations develop what we call token anxiety (the constant worry that there will not be enough available compute to meet real-time demands) and token starvation (the actual state where workloads wait for resources that are physically present but operationally unavailable).
Business requirements change constantly. A new regulatory demand arrives. Market conditions shift. A fresh application need emerges overnight. Without the ability to activate AI-ready clusters rapidly, respond to changes, and rebuild infrastructure on demand, teams stay trapped in reactive mode. Security patches, firmware updates, OS hardening, and cluster joins become weekend events instead of routine operations.
The future of enterprise AI data centers needs to be heterogeneous and adaptive. Hardware will continue to come from multiple suppliers. Workloads will span bare metal, edge, and hybrid environments. The only way to support developers and business application owners at speed is with automation that treats the entire infrastructure (compute, network, storage) as one controllable, auditable layer.
What Rapid, Rack-Scale Automation Actually Requires
To close the pit crew gap, automation must operate at the bare metal layer with three non-negotiable capabilities. It must activate AI-ready clusters in hours instead of weeks. It must support rapid rebuilds so infrastructure can adapt to evolving business requirements without disruption. And it must deliver full automation for security and patching: rebuild the node, apply firmware, patch the OS, rejoin the cluster, and validate everything, all at rack scale, even during normal business hours.
This cannot be a one-off scripting exercise. It must be a collaborative process that eliminates pain and configuration drift across network, storage, and bare metal compute. The automation must be economical (no expensive custom agents or proprietary lock-in) and universal (hardware-neutral so it works with whatever arrives next).
When implemented correctly, teams can execute these full lifecycle operations in hours, not days or weekends. They rebuild clusters during business hours when needed, maintain continuous compliance, and keep GPU utilization high because the infrastructure finally matches the speed of the models running on it.
Next Steps: Renew & Improve for AI-Ready Infrastructure
You don’t have to choose between buying faster GPUs and actually using them at scale. The path forward is to renew the substantial bare metal investment you already own and improve it with the lifecycle orchestration that eliminates token anxiety and token starvation at the source.
The RackN Digital Rebar Platform was built exactly for this reality. It provides hardware-neutral, event-driven automation that treats bare metal as the foundation for any AI workload, whether on-premises, at the edge, or in hybrid environments. Digital Rebar enables the rapid activation, rebuilds, and automated security workflows described above, all without custom VIBs or vendor lock-in. The result is a collaborative operating model that removes drift across compute, network, and storage while supporting the heterogeneous, adaptive AI data centers the industry needs.
If your teams are still wrestling with multi-week stand-up times, idle racks, and the resulting token starvation, we would like to help you map exactly where the bottlenecks live in your environment. Your next GPU rack should deliver value from day one.
Ready to close the pit crew gap?
Schedule a Digital Rebar Consultation or Infrastructure Autonomy Review. We will review your current provisioning timeline, examine your multi-vendor hardware footprint, and show how infrastructure control at the bare metal layer lets you renew from a position of strength.
Or to see how Digital Rebar makes provisioning and managing clusters quick and consistent, try our interactive demo.
| Area | Without Automated Conformance | With Automated Conformance |
|---|---|---|
| Rebuild Safety | High risk, avoided | Routine, predictable |
| Drift Detection | Reactive, manual | Continuous, enforced |
| Day 0 / Day 1 | Fragile installs | Repeatable installs |
| Operator Confidence | Low | High |
This transitioning from fragile, exception-driven operations to enforced consistency sets the stage for broader stability gains.
How Hardware Lifecycle Discipline Improves Stability Everywhere
Once automated conformance is in place, its benefits extend beyond any single platform decision. Hardware lifecycle discipline begins delivering value immediately, even before organizations change virtualization strategies.
Immediate Impact on Existing Environments
VMware environments gain consistency and stability, reducing performance variance. This makes capacity planning more accurate and reduces the length of maintenance windows by reducing the number of unknown factors. Importantly, all these improvements can be achieved without migrating to new platforms; they stem from eliminating hardware-level uncertainty.
This represents a big inflection point for bare metal and datacenter operations. You get the value of cloud-like governance without requiring complete transformation of your team.
Why Pilots Stop Stalling
When teams later evaluate OpenShift Virtualization or Kubernetes on bare metal, the experience changes dramatically. Installers stop failing unpredictably. Nodes behave consistently across rebuilds. Platform evaluation becomes a technical decision instead of an operational risk.
Governance does not guarantee success. It removes unnecessary failure modes that previously obscured the signal with noise.
Stability That Travels With the Infrastructure
Perhaps most importantly, lifecycle discipline makes stability portable. Infrastructure no longer resets to chaos when platforms change. Teams can run parallel environments, test alternatives, or adopt future platforms without rebuilding their operational foundation each time.
At this stage, infrastructure shifts from being a liability to becoming an asset.
Why Vendor-Neutral Governance Must Live Below Platforms
As stability improves across environments, another principle becomes clear: governance must remain independent of platforms to preserve flexibility. This realization naturally leads to vendor neutrality.
Neutrality Is an Architectural Decision
Vendor neutrality doesn’t emerge from licensing terms or purchasing strategy. It emerges from architecture. When lifecycle control embeds inside a single platform, infrastructure inherits that platform’s constraints, assumptions, and upgrade cadence.
Placing governance below platforms avoids this coupling. Infrastructure behaves consistently regardless of which virtualization or orchestration layer sits on top.
The Hidden Cost of Platform-Coupled Control
Platform-managed lifecycle control quietly reduces freedom by:
- Turning infrastructure upgrades into platform upgrades
- Limiting hardware choice to platform support matrices
- Binding operations to a single vendor’s roadmap
Optionality as an Operational Outcome
Vendor-neutral governance provides flexibility, allowing teams to run VMware today, evaluate OpenShift Virtualization tomorrow, and prepare for future platforms without reworking hardware processes. This stability ensures infrastructure remains consistent while platforms evolve. Flexibility indicates control, not indecision.
Ultimately, this vendor-neutral approach unlocks the primary benefit: Optionality as an Operational Outcome.
How Teams Implement Vendor-Neutral Infrastructure Governance
At this point, the theory is clear. The remaining question is practical: how do teams implement governance below the platform level without creating another silo or toolchain?
Governance Below, Platforms Above
Successful organizations separate concerns deliberately. They enforce hardware lifecycle discipline once, across all platforms. Platforms inherit clean, predictable infrastructure instead of redefining it.
This separation allows platform teams to focus on workloads and services while infrastructure teams retain ownership of physical systems.
Where RackN Fits
RackN offers a practical approach for organizations to implement a standardized hardware lifecycle management model through its RackN Digital Rebar platform. This platform operates independently of any virtualization environment and ensures compliance before any platform installations. It continuously validates, rebuilds, and maintains consistency across different environments.
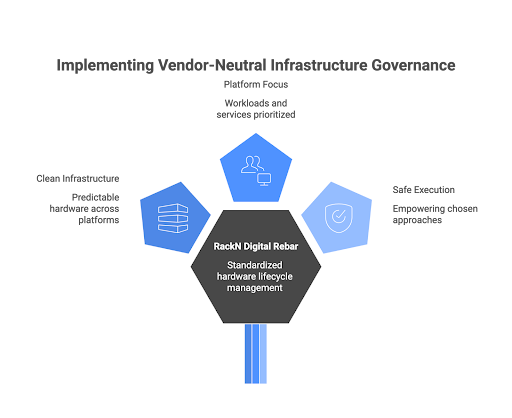
RackN supports various virtualization platforms, including VMware, OpenShift Virtualization, KubeVirt, and other platforms like Kubernetes on bare metal, without displaying any bias. It does not force organizations to migrate or follow specific strategies; instead, it empowers teams to execute their chosen approaches safely.
By instilling discipline at the infrastructure level, RackN transforms platforms into effective tools rather than potential risks.
Conclusion: Govern the Metal Before You Choose the Platform
A strong virtualization strategy can’t compensate for inadequate hardware governance. Platforms amplify the discipline in the underlying infrastructure. When governance is weak, platforms tend to fail early and visibly. Conversely, when governance is strong, platforms function as intended.
Establishing strong bare metal discipline is important for successful modernization. It stabilizes existing environments, accelerates pilot projects, and maintains vendor flexibility. Organizations that prioritize fixing governance regain control, while those that neglect it often repeat the same failures with each new platform.
If you want your virtualization efforts to succeed, start by ensuring strong governance over your hardware. If your teams are facing issues like fragile installations, stalled pilot projects, or risky rebuilds, the root of the problem likely lies beneath the platform. Assess your bare metal readiness, identify any lifecycle gaps, and standardize your hardware governance before embarking on your next VMware optimization or OpenShift Virtualization pilot.
Consider reaching out to RackN to learn how RackN Digital Rebar can help teams enforce infrastructure discipline, eliminate drift, and build virtualization strategies on a solid foundation.



